
Building a Citation Query Engine with LangChain, FAISS, and Ollama

When working with dense documents like research papers or lengthy reports, citations play a crucial role in referencing the source of information. A citation is a way of giving credit to the original text by pointing directly to the section that supports your claim. For example:
“FP4 quantization reduces memory usage by 50% compared to FP16, while maintaining accuracy [1].”
In this post, you’ll learn how to build a Citation Query Engine that:
Extracts relevant information from a document based on your query.
Generates a concise answer.
Includes inline citations that trace every fact back to its source.
By the end of this guide, you’ll have a fully functional Citation Query Engine—a powerful tool that ensures transparency, accuracy, and ease in research, summarization, and fact-checking tasks.
What Tools Will We Use?
We’ll be leveraging the following tools:
LangChain: A framework that simplifies working with large language models (LLMs) and retrieval-based systems.
FAISS: An open-source vector database designed for fast similarity search and text chunk retrieval.
LLM of Your Choice: While we demonstrate using Ollama (a framework for running local LLMs like Llama-2), you can easily swap it out with OpenAI’s GPT, Hugging Face models, or any other LLM you prefer.
Note: If you’re using Ollama, make sure it’s installed and configured on your machine. For other LLMs, just adjust the code to suit your setup.
What is a Citation Query Engine?
A Citation Query Engine allows you to ask questions about a document and receive answers that are backed by inline citations. Here’s how it works:
The engine searches the document for the most relevant sections.
It generates an answer based only on the retrieved text.
The final output includes inline citations that reference the source material for every claim.
For example, if you ask:
"What are the benefits of FP4 quantization?"
You might receive:
“FP4 quantization reduces memory usage by 50% compared to FP16, while maintaining accuracy [1]. It also improves computational efficiency, making it suitable for large-scale AI models [2].”
This ensures that every piece of information is traceable back to its source.
Architecture Overview
Let’s visualize how the Citation Query Engine works:
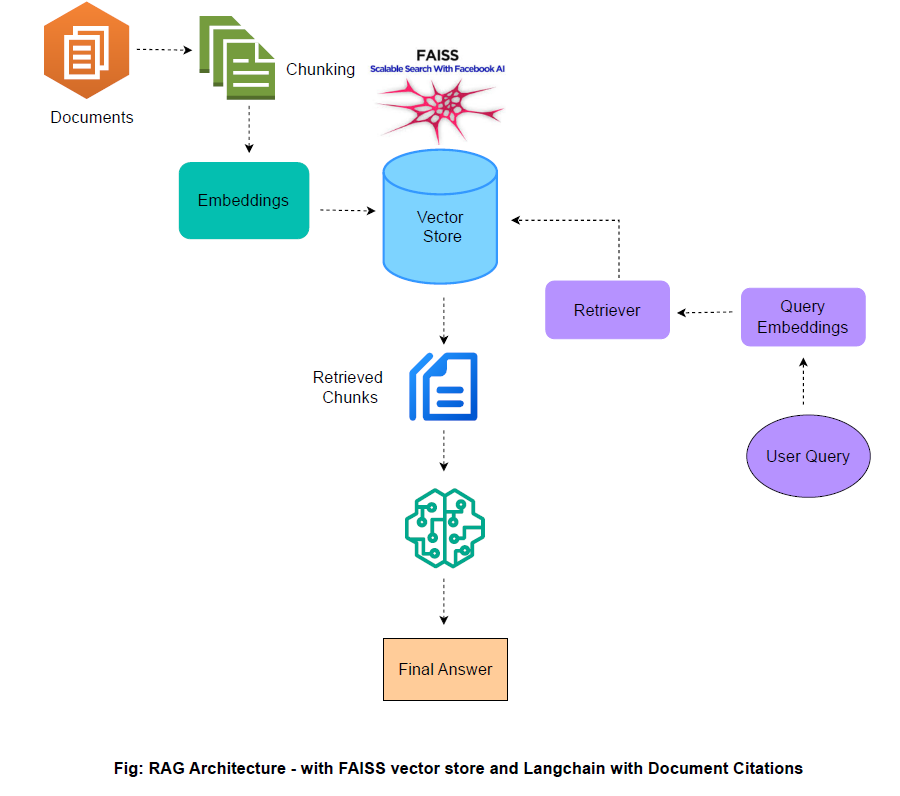
Process Breakdown:
Document Loading: The PDF is loaded and split into smaller chunks.
Embedding and Storage: Each chunk is converted into a vector embedding and stored in FAISS.
Query Retrieval: A query is transformed into an embedding, and FAISS retrieves the most similar chunks.
Answer Generation: The retrieved text is used by an LLM (via a Retrieval QA Chain) to produce an answer with inline citations.
Step 1: Setting Up the Environment
Install Required Libraries
Make sure your environment has the necessary libraries:
!pip install langchain langchain-community faiss-cpu python-dotenv ollama langchain_ollamaNote: If you’re not using Ollama, install the client library for your chosen LLM (e.g.,
openaiortransformers).
Enable Nested Asyncio (For Jupyter Users)
If you are using a Jupyter Notebook, run the following to enable nested asyncio:
import nest_asyncio
nest_asyncio.apply()Step 2: Loading and Splitting the Document
Large documents have to be divided into manageable pieces. Let’s load a sample PDF and split it into chunks.
Load the PDF
We will use LangChain’s PyPDFLoader to extract text. For this post we will be using a recent paper on fp4 quantization. Download the paper here and place in the same directory as the code directory.
# !curl -o ./data/2501.17116v1.pdf https://arxiv.org/pdf/2501.17116
from langchain_community.document_loaders import PyPDFLoader
pdf_file_path = "2501.17116v1.pdf" # Replace with your PDF's path
loader = PyPDFLoader(pdf_file_path)
documents = loader.load() # Load document in a LangChain-compatible formatSplit the Document
Due to token limits in LLMs, we split the document into smaller chunks with overlapping sections to preserve context:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Maximum length of a chunk
chunk_overlap=200 # Overlap between chunks
)
texts = text_splitter.split_documents(documents)Tip: Adjust
chunk_sizeandchunk_overlapbased on your document’s length and complexity to minimize context loss.
Step 3: Creating a Vector Store with FAISS
What is FAISS?
FAISS (Facebook AI Similarity Search) is a library that efficiently finds similar vectors in high-dimensional space. Think of each text chunk as having a unique “fingerprint” (embedding). FAISS allows us to quickly search through these embeddings to find the most relevant matches.
Generate Embeddings
We use an LLM via Ollama (or any other provider) to create embeddings:
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="nomic-embed-text") # ollama pull nomic-embed-textStore the Embeddings in FAISS
Store your text chunk embeddings into FAISS:
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(texts, embeddings)Step 4: Retrieving Relevant Chunks
Once the FAISS vector store is populated, we can retrieve relevant chunks using the query's embedding.
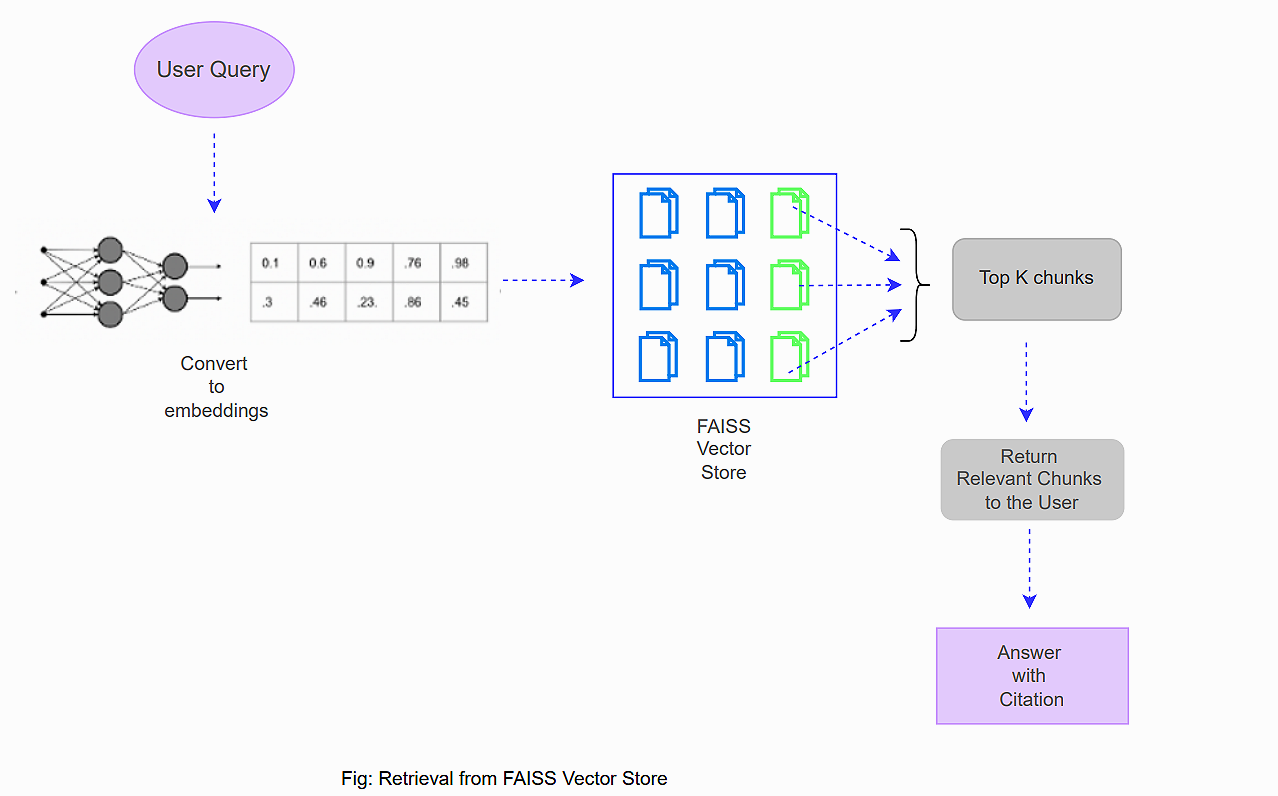
How Retrieval Works
The user begins by entering a query.
The system converts the query into an embedding.
FAISS searches through its vector database using the embedding.
The system retrieves the most relevant text segments.
These segments are returned to the user for further processing (e.g., used as context in generating an answer with inline citations).
Example Retrieval Code
# Create retriever from FAISS vector store
retriever = vectorstore.as_retriever()
retrieved_chunks = retriever.get_relevant_documents("What are the benefits of FP4 quantization?")
for i, chunk in enumerate(retrieved_chunks):
print(f"Chunk {i+1}: {chunk.page_content}")Let’s look at the output:
Chunk 1: 2022), directly-casted FP4, and our FP4 method. We
use W4A4 to denote direct quantization, meaning that
quantizing both weight and activation to fp4. Meanwhile,
W4A4+DGE+OCC denotes our fp4 quantization method
that incorporates the Differentiable Gradient Estimator
(DGE) and Outlier Clamp and Compensation (OCC) meth-
ods introduced in Section 3. The loss curves show that two
FP8 methods and our FP4 approach maintain pretraining ac-
curacy, while directly-casted FP4 has a significant training
loss gap.
Weights. For weight-only 4-bit quantization (W4A8),
6
Chunk 2: Optimizing Large Language Model Training Using FP4 Quantization
Impact Statement
This work demonstrates the feasibility of using ultra-low
precision formats like FP4 for training large language mod-
els, offering a pathway toward energy conservation and re-
duced carbon emissions in AI development. By significantly
lowering computational and memory demands, FP4-based
methods can democratize access to advanced AI systems
while promoting environmental sustainability.
Additionally, this research calls for next-generation AI accel-
erators optimized for 4-bit computations, potentially shap-
ing future hardware innovations. However, broader societal
implications must be considered, including the risks of mis-
...Step 5: Setting Up the Retrieval QA Chain
A Retrieval QA Chain stitches together the retrieval of text chunks and question-answering to ensure the answer is fully evidence-based.
Define a Custom Prompt
The custom prompt directs the LLM to answer questions using the retrieved documents and include inline citations:
from langchain.prompts import PromptTemplate
prompt_template = """
You are an expert assistant that answers questions solely using the information provided in the documents below. When stating any factual claim, immediately include an inline citation in the format [number] right after the claim. The citation number must correspond to the document that supports that fact.
For example:
Using ultra-low precision formats like FP4 can significantly lower computational and memory demands, contributing to energy conservation and reduced carbon emissions in AI development [1].
Do not provide a separate bibliography or list of sources at the end; include only inline citations within your answer.
Documents:
{context}
Question: {question}
Answer:
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
Build the Retrieval QA Chain
Combine the retrieval mechanism with an LLM to generate the answer:
from langchain.chains import RetrievalQAWithSourcesChain
from IPython.display import Markdown, display
from langchain.llms import Ollama # Replace with your preferred LLM if necessary
llm = Ollama(model="phi4") # ollama pull phi4
# Set up the RetrievalQAWithSourcesChain,
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
chain_type_kwargs={
"prompt": prompt,
"document_variable_name": "context"
},
return_source_documents=True
)
Note: The chain ensures that the LLM generates an answer based solely on the documents provided, reducing the risk of hallucination.
Step 6: Querying the Engine
With everything in place, it’s time to ask a question and see the Citation Query Engine in action!
Submit a Query
query = "What are the key benefits of FP4 quantization?"
result = qa_chain.invoke({"question": query})
display(Markdown(result["answer"])) # Display answer with inline citationsThe key benefits of FP4 quantization include:
Energy Conservation and Reduced Carbon Emissions: Using ultra-low precision formats like FP4 significantly lowers computational and memory demands, contributing to energy conservation and reduced carbon emissions in AI development [2].
Democratizing Access to Advanced AI Systems: By lowering the requirements for computational resources, FP4-based methods can make advanced AI systems more accessible to a wider audience [2].
Promoting Environmental Sustainability: The reduction in resource demand inherently supports environmental sustainability initiatives by minimizing energy consumption and associated emissions [2].
Maintaining Pretraining Accuracy: The use of FP4 quantization maintains pretraining accuracy comparable to higher precision formats like FP8 or FP16, which helps in reducing the accuracy gap between different precision levels [1].
Feasibility for Large Language Models (LLMs): It establishes a viable approach to training large language models using ultra-low precision, overcoming challenges related to limited dynamic range and quantization precision in 4-bit formats [3].
Encouraging Future Hardware Innovations: The work calls for next-generation AI accelerators optimized for 4-bit computations, which could shape future hardware designs [2].
These benefits highlight both the technical advantages of FP4 quantization in terms of performance and resource efficiency, as well as its potential impact on accessibility and sustainability in AI development.Display the Source Documents
Transparency is key. Retrieve and display the source documents used to generate the answer:
markdown_output = "sources:\n\n"
for idx, doc in enumerate(result["source_documents"], start=1):
markdown_output += f"{idx}. metadata: {doc.metadata}, Text: {doc.page_content}\n\n"
markdown_output += "---\n\n"
display(Markdown(markdown_output))
Final Thoughts
Congratulations! You have now built a fully functional Citation Query Engine using LangChain, FAISS, and your LLM of choice. This engine not only extracts and processes relevant information from large documents but also provides answers with inline citations for enhanced transparency and reliability.